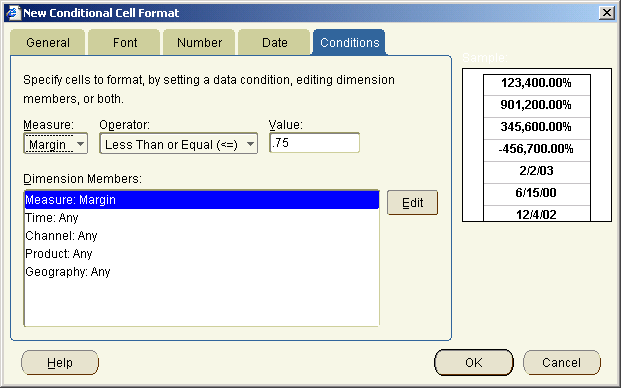
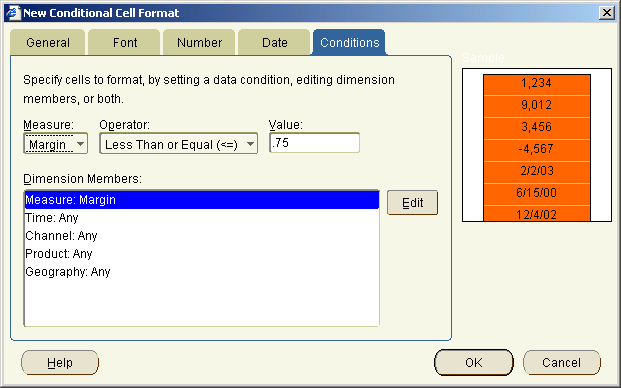
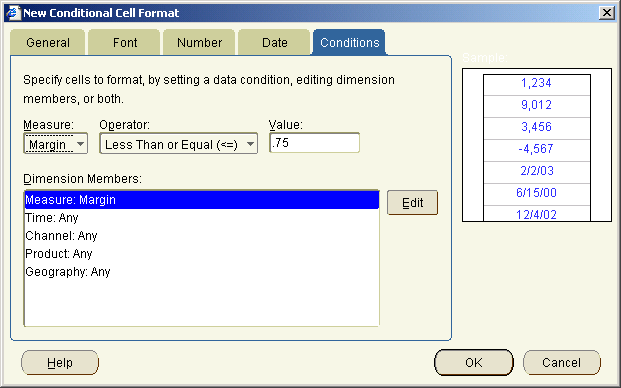
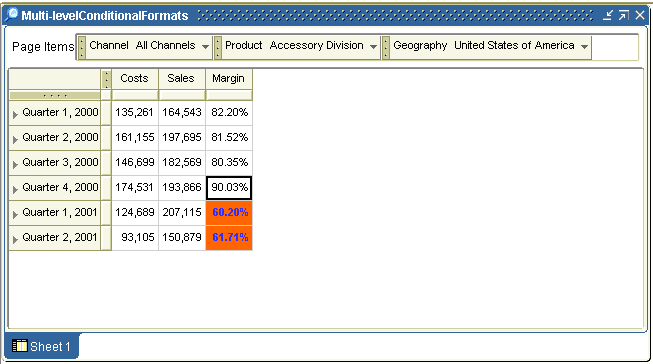
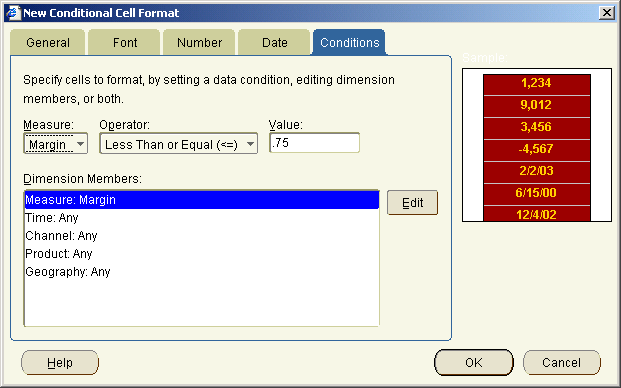
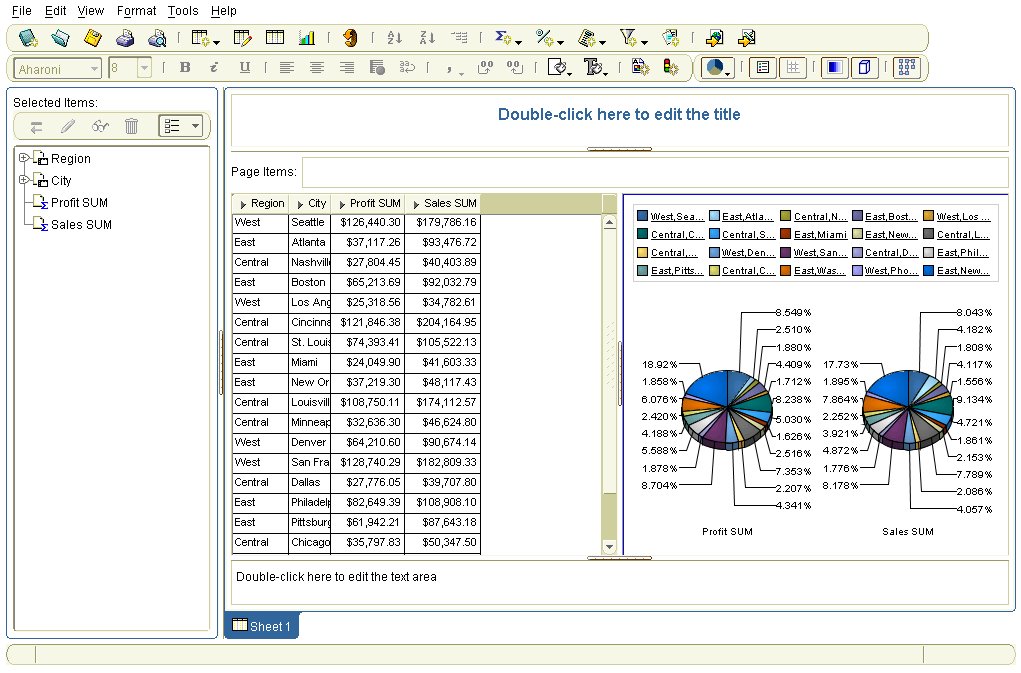
In the process of creating this sample I discovered a number of issues that lead to some new features within BI Beans 10g. Most of the issues of combining server side programming (OLAP DML) with JSP development is actually debugging the whole stack. JDeveloper provides excellent JSP debugging tools and the JDev team have some excellent samples that can be found on their OTN home page.
However, trying to debug OLAP DML was not quite as easy. So as part of BI Beans10g we provided some additional debugging facilities to help OLAP DML developers. A generic AW is used to debug any OLAP DML operation that is called from a JSP page. This AW is shipped as part of the Common Schema samples and is usually installed into the CS_OLAP schema and is called AWDEBUG. It contains a program that controls the whole debug process, called BI_BEANS_UTIL. That program takes the following arguments:
- Context Name passed from Java Environment
- Current directory setting
- Name of calling program
- Mode of operation - START or STOP
- Should prgtrace be enabled
- Should badline be enabled
- Should monitor be enabled
- Should trackprg be enabled
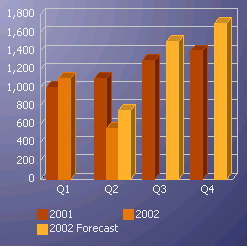
To show how the debugging process works lets review the What-If JSP page that is part of the Executive Insight demo. The page contains two buttons above the bar graph:
- Run Model – executes a new forecast using the OLAP DML program RUN_MODEL
- Reset – clears forecasted data using the OLAP DML program CLEAR_DATA

To enable the debugging process the AWDEBUG workspace needs to be attached to the current session. This is done using an AWCommand tag. The tag is added to the start of JSP page and is set to manually execute. Other options are “onRender” or “onInit” and these are self-explanatory.

The wizard that defines the tag allows the developer to type any OLAP DML command into a window. These are the commands that will be executed when the tag is called.

For this example, we attach the AW UTILS that contains the programs that will create the forecast data and also remove the forecast data for the “Reset” button. The second command attaches the AW that controls debugging.
The next step is to add the two buttons that will execute the OLAP DML and update the graph with the new data. These buttons can be defined using the AWProgram JSP Tag. The tag wizard prompts for the required inputs. The key fields are as follows:
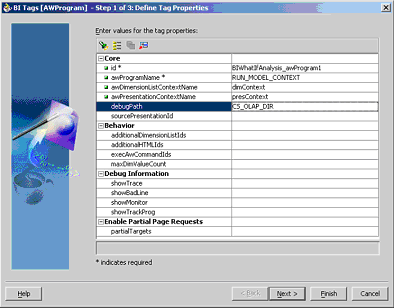
- debugPath – this is the name of a directory object created within the database instance and points to a directory path on the server. All trace files will be written to this directory
- ShowTrace – enable trace of each line of code. This sets the OLAP DML option called PRGTRACE. This generates a file called program_name_PRGTRACE_timestamp.trc
- ShowBadLine – enables verbose error messages
- ShowMonitor – enables recording of execution timings of each line of code. This generates a file called program_name_MONITOR_timestamp.trc
- ShowTrackprg - enables recording of execution timings of each program. This generates a file called program_name_TRACK_timestamp.trc
Each file is written to the directory specified in the debugPath property. All tracing is enabled only for the duration of the execution of the tag. Once the tag has finished firing all tracing is automatically disabled.
The three files that are generated contain different information and are used to debug different situations. Once an OLAP DML program has been defined the next step is to ensure it is executing correctly. The execution path can be traced using the showTrace property. This will show, line by line, the flow of the program. Assuming the program is running correctly but performance is not as expected you can use the showTrackprg and showMonitor properties to evaluate how much time is being spent within each program and on each line within each program. This can highlight lines of code that are taking a long time to execute and that need optimizing. I will provide a detailed review of each of these trace files in the next article.